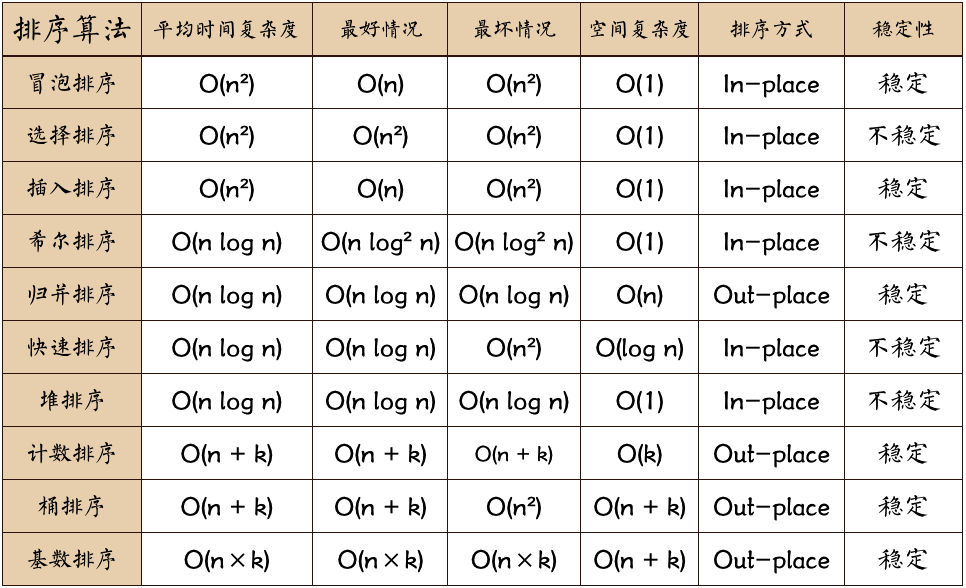
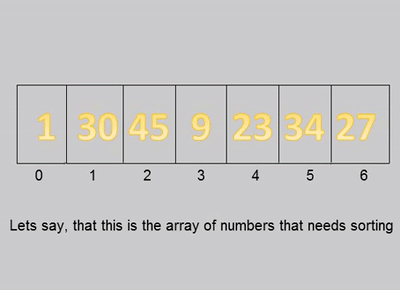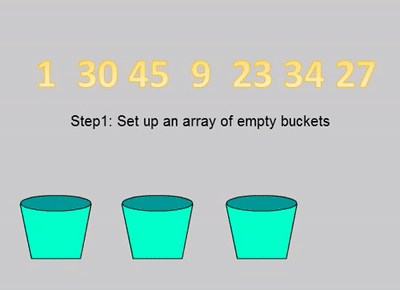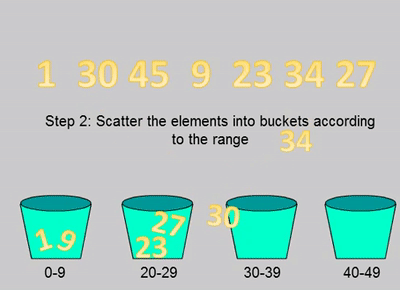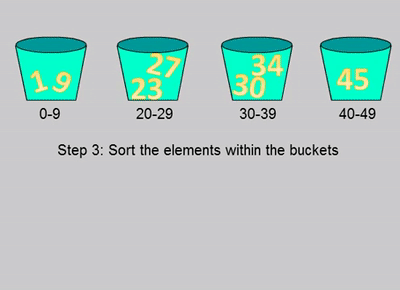defbubble_sort(nums: List[int]) -> List[int]: n=len(nums) for i inrange(n): for j inrange(1,n-i): if nums[j-1]>nums[j]: nums[j-1],nums[j]=nums[j],nums[j-1] return nums
defselection_sort(nums: List[int]) -> List[int]: n=len(nums) for i inrange(n): min=i for j inrange(min+1,n): if nums[j]<nums[min]: min=j nums[min],nums[i]=nums[i],nums[min] return nums
definsertion_sort(nums: List[int]) -> List[int]: for i inrange(1,len(nums)): if nums[i]<nums[i-1]: temp,j=nums[i],i while j>0and temp<nums[j-1]: nums[j]=nums[j-1] j-=1 nums[j]=temp return nums
defshell_sort(nums: List[int]) -> List[int]: h=1 while h < len(nums): h=3*h+1 while h>=1: for i inrange(h,len(nums)): if nums[i]<nums[i-h]: temp,j=nums[i],i while j>0and temp<nums[j-h]: nums[j]=nums[j-h] j-=h nums[j]=temp h=h//3 return nums
defheap_sort(nums: List[int]) -> List[int]: defsink(k,last): whileTrue: j=2*k+1 if j>last: break if j<last and nums[j]<nums[j+1]: j+=1 if nums[k]>=nums[j]: break nums[k],nums[j]=nums[j],nums[k] k=j n=len(nums) for k inrange(n//2,-1,-1): #构造大顶堆 sink(k,n-1) k=n-1 while k>0: nums[0],nums[k]=nums[k],nums[0] k-=1 sink(0,k) return nums
defcount_sort(nums: List[int]) -> List[int]: _min=50000#排序数组的最大值 _max=-50000#排序数组的最小值 for n in nums: _min=min(n,_min) _max=max(n,_max) counter=[0]*(_max-_min+1) for n in nums: counter[n-_min]+=1 j=0 for i inrange(len(nums)): while counter[j]==0: j+=1 nums[i]=j+_min counter[j]-=1 return nums
defbucket_sort(nums: List[int], bucketSize: int) -> List[int]: iflen(nums)<2: return nums _min=50000#排序数组的最大值 _max=-50000#排序数组的最小值 for n in nums: _min=min(n,_min) _max=max(n,_max) bucketCnt = (_max - _min) // bucketSize + 1 buckets = [[] for _ inrange(bucketCnt)] for n in nums: buckets[(n - _min) // bucketSize].append(n) res = [] for b in buckets: ifnot b: continue if bucketSize==1: res+=b else: if bucketCnt==1: bucketSize-=1 res+=bucket_sort(b,bucketSize) return res
defradix_sort(nums: List[int]) -> List[int]: _min=50000#排序数组的最大值 _max=-50000#排序数组的最小值 for n in nums: _min=min(n,_min) _max=max(n,_max) maxDigit = len(str(_max-_min)) buckets = [[] for _ inrange(10)] div, mod = 1, 10 for _ inrange(maxDigit): for n in nums: buckets[(n-_min) % mod // div].append(n-_min) i = 0 for j inrange(10): for n in buckets[j]: nums[i] = n+_min i += 1 buckets[j].clear() div *= 10 mod *= 10 return nums