Kubernetes的简单介绍和基本原理
Kubernetes在企业中应用场景
- 自动化运维平台
- 中小型企业,使用k8s构建一套自动化运维平台(降本增效)
- 大型互联网公司更要使用
- 充分利用服务器资源
- 服务无缝迁移
服务部署模式变迁以及服务部署模式变化的问题思考
- 服务部署模式是如何变迁的?
- 物理机部署(就是直接把服务部署在物理机上面)
- 虚拟化方式(就是把服务部署在虚拟机中,虚拟机分割物理资源—-充分利用服务器资源)
- 容器化方式进行部署
- 服务部署模式变化,带来哪些问题?
- 前提条件:SOA架构,微服务架构模式下,服务拆分越来越多,部署维护的服务越来越多,如此多的服务如何去管理?
- 虚拟机服务部署方式(openstack)
- 容器化部署模式(k8s —- 管理容器)
- 面临问题:SOA架构,微服务架构模式下,服务拆分越来越多,部署维护的服务越来越多,面临什么样的问题?
- 如何对服务进行横向扩展
- 容器宕机怎么办?数据怎么恢复
- 重新发布新的版本如何更新,更新后不影响业务
- 如何监控容器
- 容器如何调度创建
- 数据安全性如何保证
- 解决方案:使用k8s管理容器,以上的问题,k8s都可以完美解决
- 前提条件:SOA架构,微服务架构模式下,服务拆分越来越多,部署维护的服务越来越多,如此多的服务如何去管理?
云架构 & 云原生
- 云和k8s是什么关系?
- 云就是使用容器构建的一套服务集群网络,云由很多的大量容器构造
- k8s就是用来管理云中的容器
- 云架构
- iaas:基础设施即服务
- 用户:租用(购买|分配权限)云主机,用户就不需要考虑网络,DNS,存储,硬件环境方面的问题。
- 运营商:提供网络,存储,DNS,这样的服务就叫做基础设施服务
- paas:平台即服务
- 提供MYSQL\ES\MQ\……
- saas:软件即服务
- 比如钉钉,财务管理软件
- serverless:无服务(不需要服务器)
- 站在用户的角度考虑问题,用户只需要使用云服务器即可,在云服务器所有的基础环境,软件环境都不需要用户自己安装
- 未来服务开发都是serverless,企业都构建了自己的私有云环境,或者是使用公有云环境
- iaas:基础设施即服务
- 云原生
- 就是为了让应用程序(项目,服务软件)都运行在云上的解决方案,这样的方案就叫做云原生
- 特点:
- 容器化:所有的服务都必须部署在容器中
- 微服务:web服务架构是微服务架构
- CI/CD:可持续交付和可持续部署
- DevOps:开发和运维密不可分
kubernetes架构原理
- kubernetes是google公司使用go语言开发,前身是borg系统
- kubernetes架构
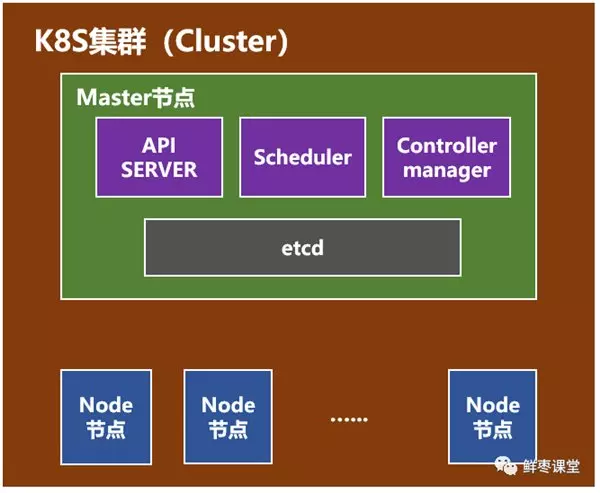
- master 节点
- api server:k8s网关,所有的指令请求都必须经过api server
- scheduler:调度器,使用调度算法,把请求的资源调度到某一个node节点
- controller:控制器,维护k8s资源对象
- etcd:存储资源对象
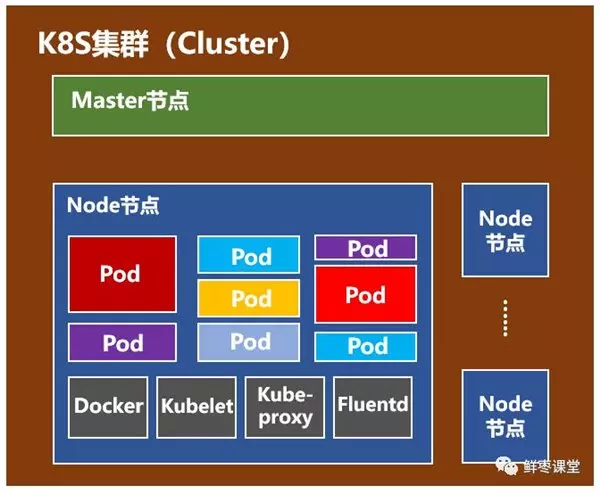
- node 节点
- docker:运行容器的基础环境,容器引擎
- kubelet:在每一个node节点都存在一份,在node节点上的资源操作指令由kubelet来执行,负责本地pod的维护
- kube-proxy:代理服务,负载均衡。在多个pod之间来做负载均衡。
- fluentd:日志收集服务
- pod:是k8s管理的基本单元(最小单元),pod内部是容器。k8s不直接管理容器,而是管理pod。pod内部可以有一个容器,或者是多个容器。
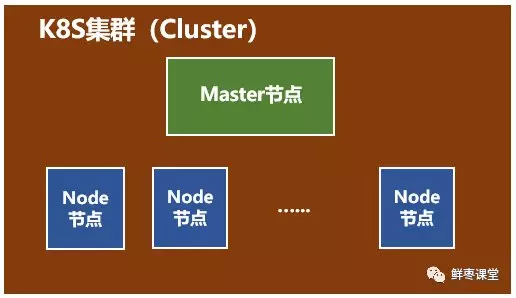
- 关系:一个master对应一群node节点
- master 节点
kubernetes核心组件原理
pod核心原理
- pod是什么?
pod也是一个容器(这个容器装的是docker创建的容器,pod是一个用来封装容器的容器),pod是一个虚拟化分组(pod有自己的IP地址,主机名),相当于一台独立沙箱环境。pod相当于独立主机,可以封装一个或者多个容器。 - pod用来干什么?
通常情况下,在服务部署时候,使用pod来管理一组相关的服务。(一个pod中要么部署一个服务,要么部署一组有关系的服务)
一组相关的服务:在链式调用的调用链路上的服务,叫做一组相关的服务。
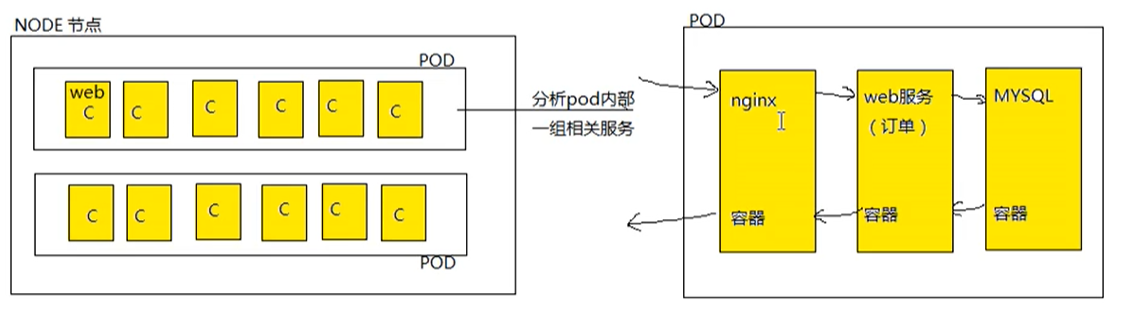
- web服务集群如何实现?
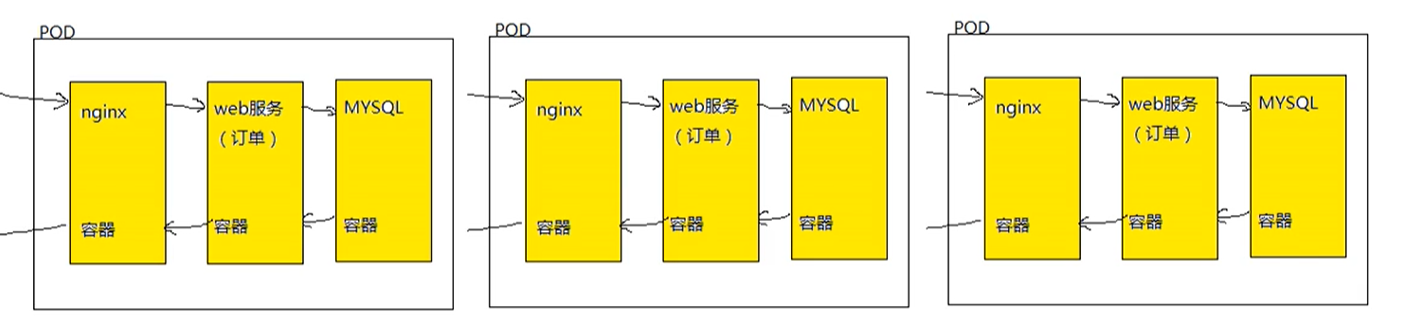
只需要复制多份pod的副本即可,这也是k8s管理的先进之处,k8s如果进行扩容或者缩容,只需控制pod的数量即可。 - pod底层网络,数据存储是如何进行的?
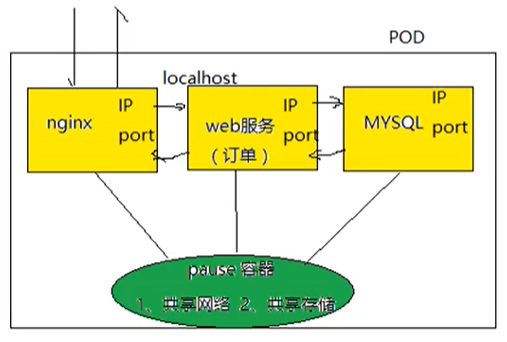
- pod内部容器创建之前,必须先创建pause容器
- 服务容器之间访问使用localhost访问,相当于访问本地服务一样,性能非常高。
ReplicaSet副本控制器
副本控制器有2种:ReplicaSet和ReplicationController
- 副本控制器作用:
控制pod副本(服务集群)的数量,永远与预期设定的数量保持一致。例如:当副本设置为3的时候,副本控制器将会永远保证副本数量为3,当有pod服务宕机的时候,副本控制器会立即重新创建一个新的pod,永远保证副本数量为3。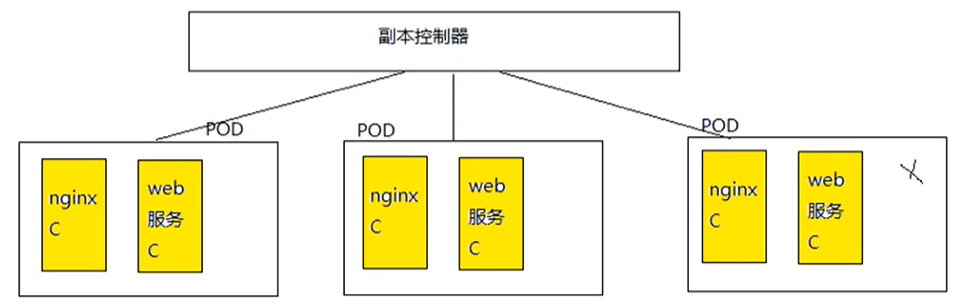
- ReplicaSet和ReplicationController有什么区别?
- ReplicaSet可以单选和复合选择
- ReplicationController只能单选
副本控制器通过标签选择器维护它关联的pod副本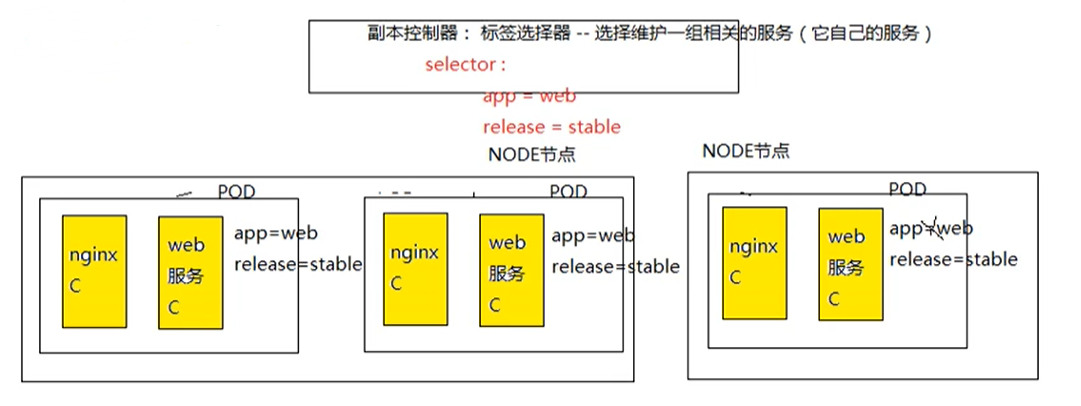
在新版的k8s中,建议使用ReplicaSet作为副本控制器,ReplicationController不再使用了。
Deployment部署对象
- 服务部署结构模型
- 滚动更新
ReplicaSet副本控制器控制pod副本的数量。但是:项目的需求在不断迭代,不断的更新,项目版本将会不停的发版,版本的变化,如何做到服务更新?
ReplicaSet不支持滚动更新,Deployment对象支持滚动更新。通常和ReplicaSet一起使用。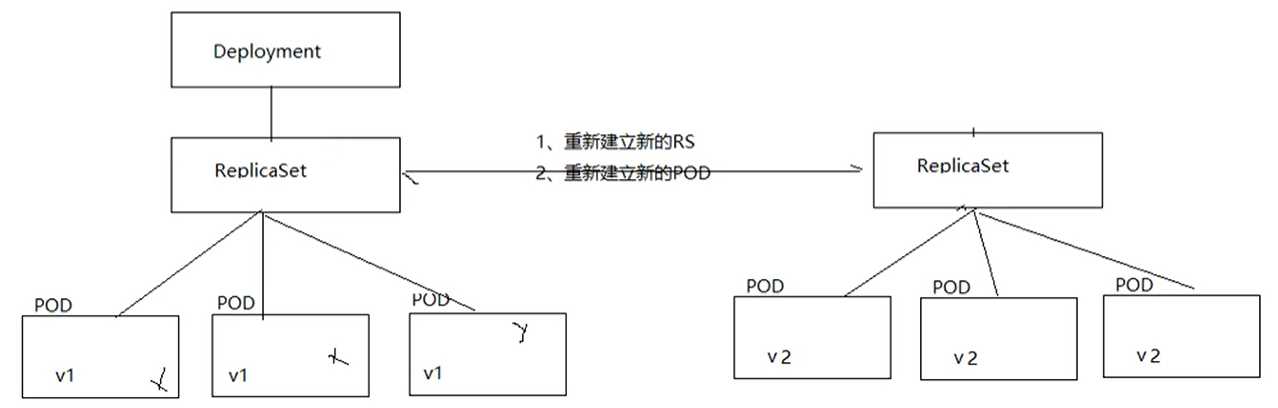
StatefulSet有状态服务部署对象
为了解决有状态服务使用容器化部署的问题
- 部署模型
- 有状态服务
- 思考:MYSQL使用容器化部署,存在什么样的问题?
- 容器是有生命周期的,一旦宕机,数据丢失
- pod部署,pod有生命周期,数据丢失
- 总结:
k8s来说,不能使用deployment部署有状态服务。通常情况下,deployment被用来部署无状态服务。那么对于有状态服务的部署,使用StatefulSet进行有状态服务的部署。 - 状态服务的解释:
- 有状态服务:
- 有实时的数据需要存储
- 有状态服务集群中,把某一个服务抽离出去,一段时间后再加入集群网络,集群网络将无法使用
- 无状态服务:
- 没有实时的数据需要存储
- 无状态服务集群中,把某一个服务抽离出去,一段时间后再加入集群网络,对集群服务没有任何影响
- 有状态服务:
- StatefulSet部署模型:
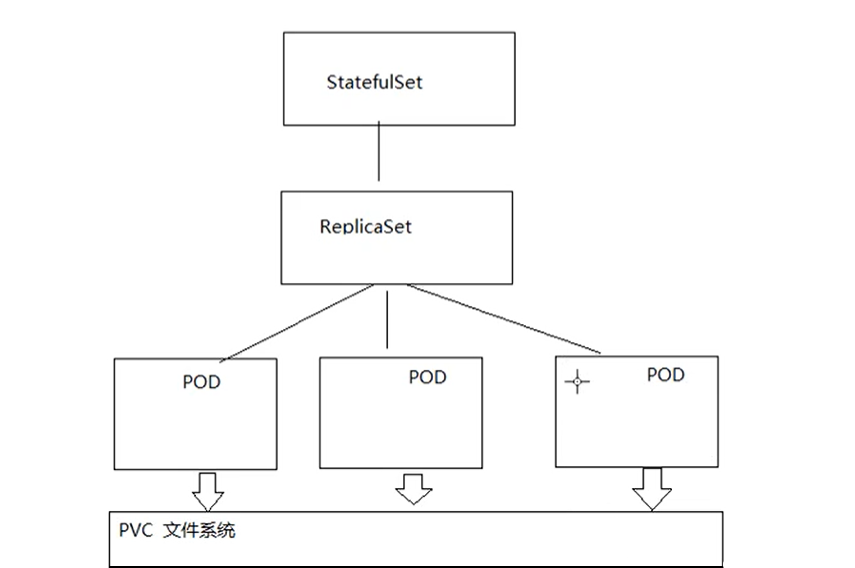
StatefulSet保证pod重新建立后,hostname不会发生变化,pod就可以通过hostname来关联数据。
kubernetes服务的注册与发现
pod核心结构
- pod相当于一个容器,pod有独立ip地址,也有自己的hostname,利用namespace进行资源隔离,独立沙箱环境
- pod内部封装的是容器,可以封装一个,或者多个容器(通常是一组相关的容器)
- pod内部容器之间采用localhost访问。
- pod如何对外提供服务访问:
- pod是虚拟的资源对象(进程),没有对应实体(物理机,物理网卡)与之对应,无法直接对外提供服务访问。
- pod如果要对外提供服务,必须绑定物理机端口(在物理机上开启端口,让这个端口和pod的端口进行映射),这样可以通过物理机进行数据包的转发。
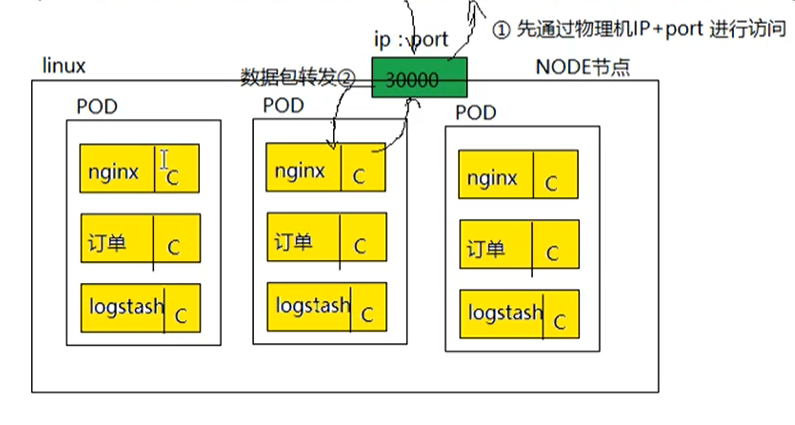
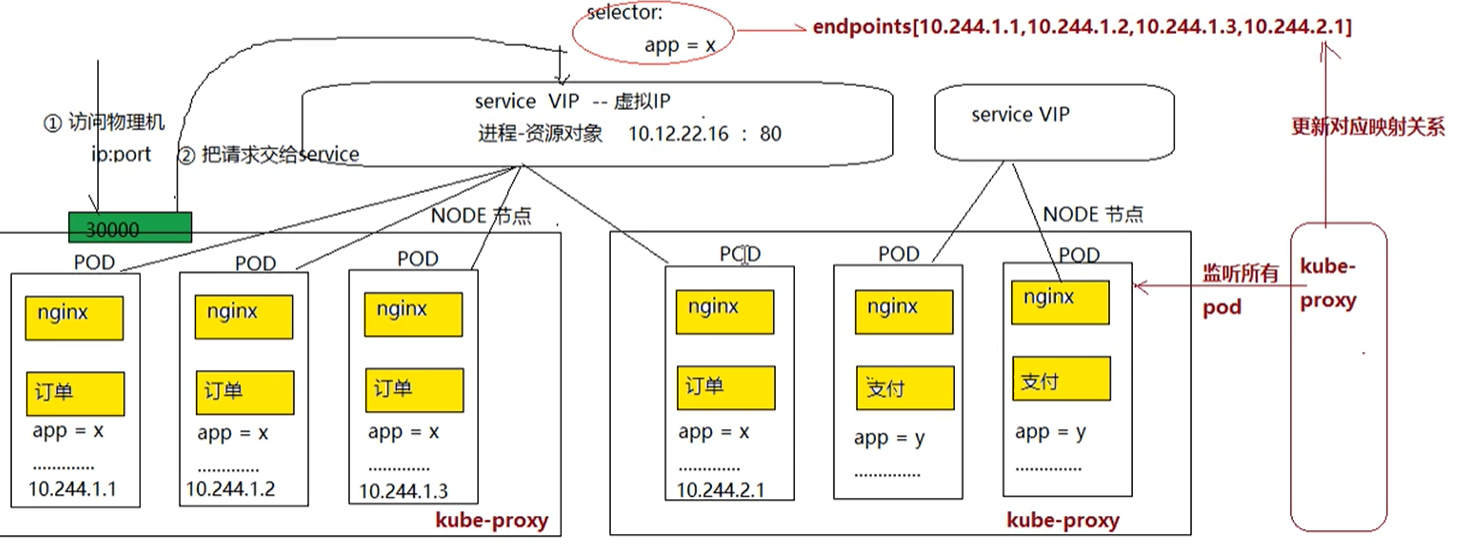
Service实现负载均衡
- 什么是service资源对象?
- pod IP:pod的ip地址
- node IP:物理机的ip地址
- cluster IP:虚拟ip,是由k8s抽象出来的service对象,这个service对象就是一个vip(虚拟ip)的资源对象
- service vip转发原理
- service和pod都是一个进程,service也不能对外提供服务
- sercie和pod之间可以直接进行通信,它们的通信属于局域网通信
- 把请求交给service后,service使用(iptables,ipvs)做数据包的分发
- service和一组pod副本通过标签选择器进行关联
- 通过kube-proxy监听pod,一旦pod宕机或者更新,kube-proxy会通知service更新pod的映射关系
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 CodeTime!


评论