搭建ElasticSearch集群
1 单点的问题
单台服务器,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用。单点的elasticsearch也是一样,那单点的es服务器存在哪些可能出现的问题呢?
- 单台机器存储容量有限
- 单服务器容易出现单点故障,无法实现高可用
- 单服务的并发处理能力有限
所以,为了应对这些问题,我们需要对elasticsearch搭建集群。
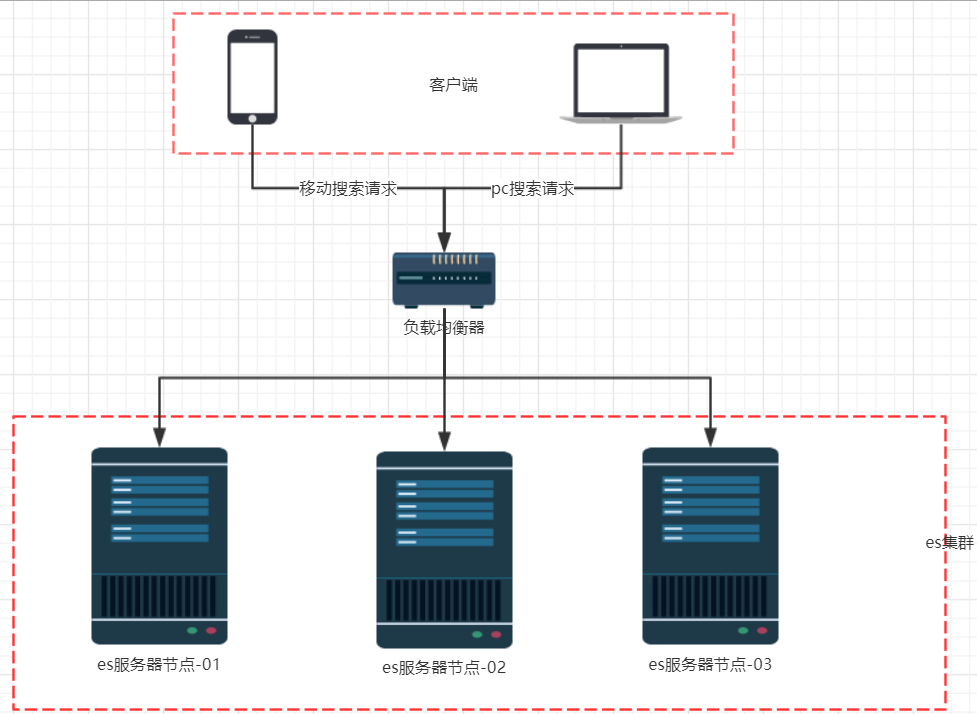
数据分片
首先,我们面临的第一个问题就是数据量太大,单点存储量有限的问题。我们可以把数据拆分成多份,每一份存储到不同机器节点(node),从而实现减少每个节点数据量。
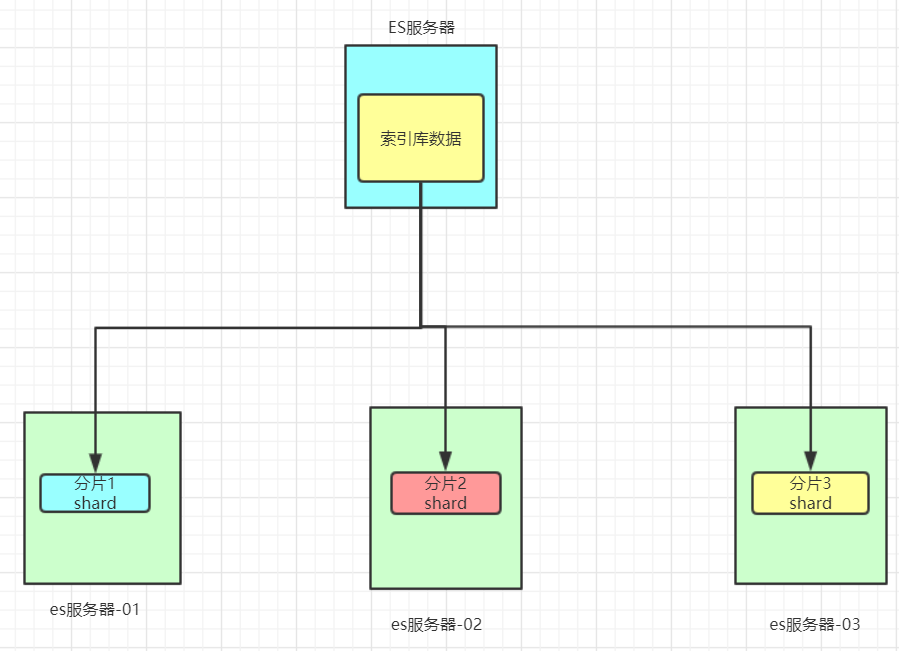
数据备份
数据分片解决了海量数据存储的问题,但是如果出现单点故障,那么分片数据就不再完整,这又该如何解决呢?
就像大家为了备份手机数据,会额外存储一份到移动硬盘一样。我们可以给每个分片数据进行备份,存储到其它节点,防止数据丢失,这就是数据备份,也叫数据副本(replica)。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
- 首先对数据分片,存储到不同节点
- 然后对每个分片进行备份,放到对方节点,完成互相备份
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:
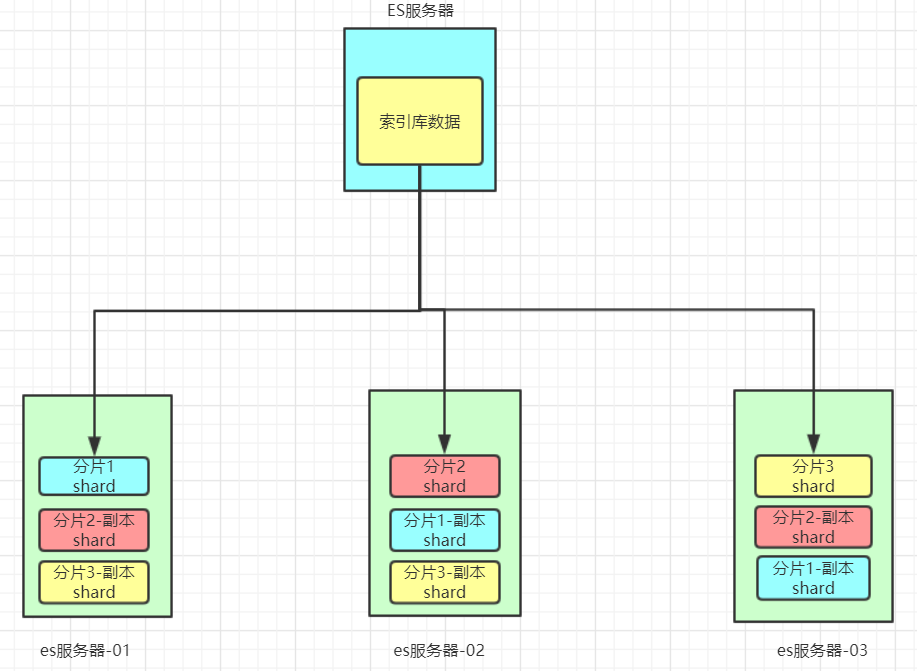
在这个集群中,如果出现单节点故障,并不会导致数据缺失,所以保证了集群的高可用,同时也减少了节点中数据存储量。并且因为是多个节点存储数据,因此用户请求也会分发到不同服务器,并发能力也得到了一定的提升。
2 搭建集群
集群需要多台机器,我们这里用一台机器来模拟,因此我们需要在一台虚拟机中部署多个elasticsearch节点,每个elasticsearch的端口都必须不一样。
我们计划集群名称为:heima-elastic,部署3个elasticsearch节点,分别是:
- node-01:http端口9201,TCP端口9301
- node-02:http端口9202,TCP端口9302
- node-03:http端口9203,TCP端口9303
接下来的所有操作,记得要使用elastic用户来操作!
另外,建议先对当前虚拟机进行快照,以后好恢复成单点结构。
1. 清空elasticsearch中的数据
首先把已经启动的elasticsearch关闭,然后通过命令把之前写入的数据都删除。
1 | |
2. 修改elasticsearch配置
进入/home/elastic/elasticsearch/config目录,修改elasticsearch.yml文件
1 | |
内容修改成这样:
1 | |
3. 复制elasticsearch节点
回到 /home/elastic目录,将elasticsearch目录修改为ealsticsearch-01:
1 | |
然后输入下面命令,拷贝两份elasticsearch实例:
1 | |
进入elasticsearch-02/config目录,修改elasticsearch.yml中的下列配置:
1 | |
注意到,注意是把01改成了02,但不是所有,切勿自动全局替换!
同理,进入elasticsearch-3/config/,修改elasticsearch.yml文件,与上面类似,不过修改成03。
4. 启动并测试
分别启动3台elasticsearch,可以用后台启动方式(要使用elastic用户来操作):
1 | |
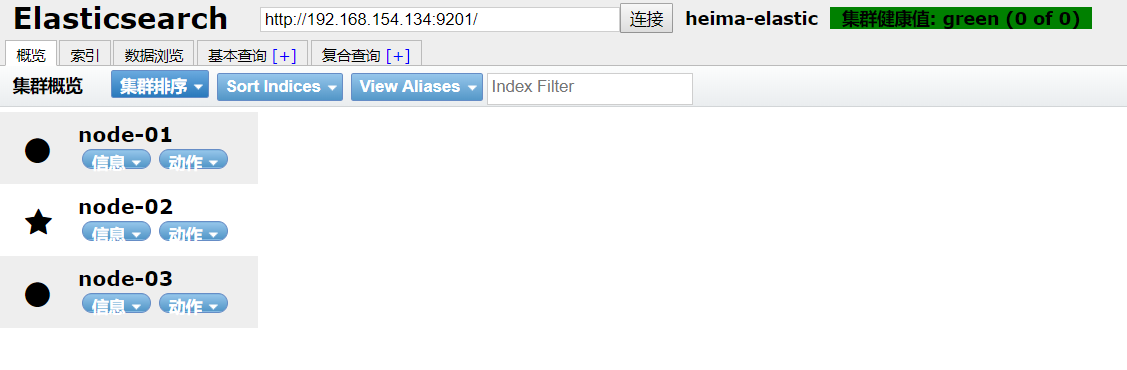
通过启动运行chrome的 elasticsearch-head插件,可以查看到节点信息:
5. 启动错误
启动错误1:
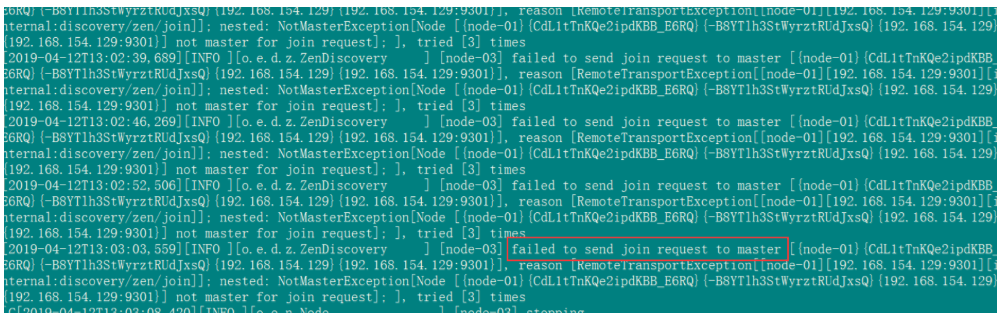
原因是:是因为复制的elasticsearch文件夹下包含了data文件中示例一的节点数据,需要把示例二data文件下的文件清空。删除es集群data数据库文件夹下所有文件即可。
启动错误2:

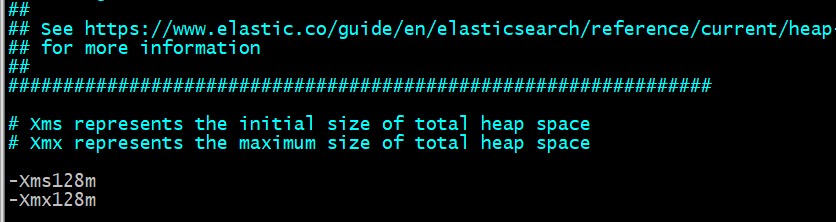
由于elasticsearch6.8默认分配jvm空间大小为1g,虚拟机内存不够大,修改jvm空间分配128m或256m、512m,最少需要128m。
6. 集群健康
可以通过elasticsearch-head插件查看集群健康状态,有以下三个状态:

- green:所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
- yellow:所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果更多的分片消失,你就会丢数据了。把
yellow想象成一个需要及时调查的警告。 - red:至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
3 测试集群中创建索引库
搭建集群以后就要创建索引库了,那么问题来了,当我们创建一个索引库后,数据会保存到哪个服务节点上呢?如果我们对索引库分片,那么每个片会在哪个节点呢?
这个要亲自尝试才知道。还记得创建索引库的API吗?
- 请求方式:PUT
- 请求路径:/索引库名
- 请求参数:json格式:
1 | |
settings:就是索引库设置,其中可以定义索引库的各种属性,目前我们可以不设置,都走默认。
这里给搭建看看集群中分片和备份的设置方式,示例:
1 | |
这里有两个配置:
- number_of_shards:分片数量,这里设置为3
- number_of_replicas:副本数量,这里设置为1,每个分片一个备份,一个原始数据,共2份。
通过chrome浏览器的head查看,我们可以查看到分片的存储结构:
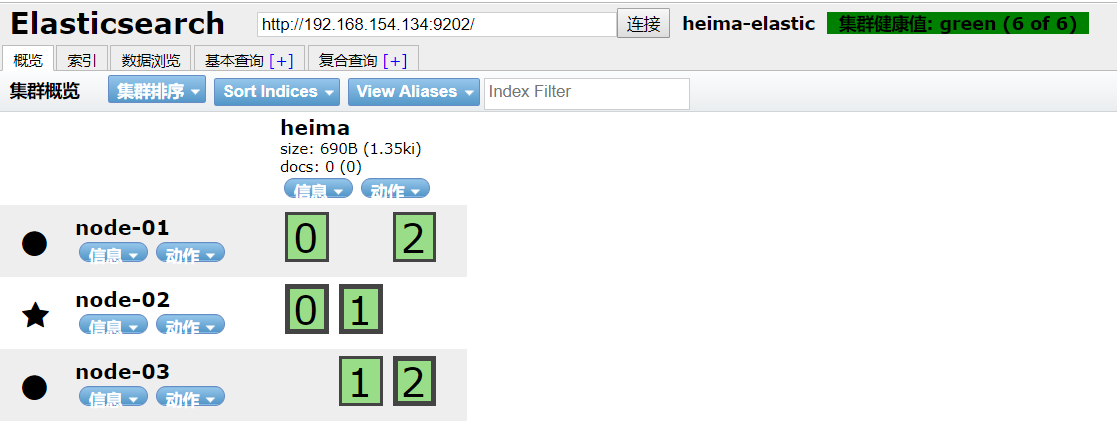
可以看到,heima这个索引库,有三个分片,分别是0、1、2,每个分片有1个副本,共6份。
- node-01上保存了0号分片和1号分片的副本
- node-02上保存了1号分片和2号分片的副本
- node-03上保存了0号分片和2号分片的副本


